Real-Time Biker Classifier With Synthetic Dataset Generator
Key Points
- Usage of synthetic datasets to augment deep learning solutions to improve accuracy.
- Shedding of neural network layers to meet speed requirements on CPU.
Synthetic Dataset
Two common problems that plague deep-learning based solutions are data acquisition and computational resources. While the former can sometimes be alleviated with public datasets, these data are only available for common objects of study such as pedestrians. To obtain data for more niche objects, such as bikers in this case, one would often have to resort to manual data collection. This process can be time consuming or even infeasible when trying to collect large volumes of data. To overcome this challenge, a method to generate synthetic datasets is proposed.
Data Baseline
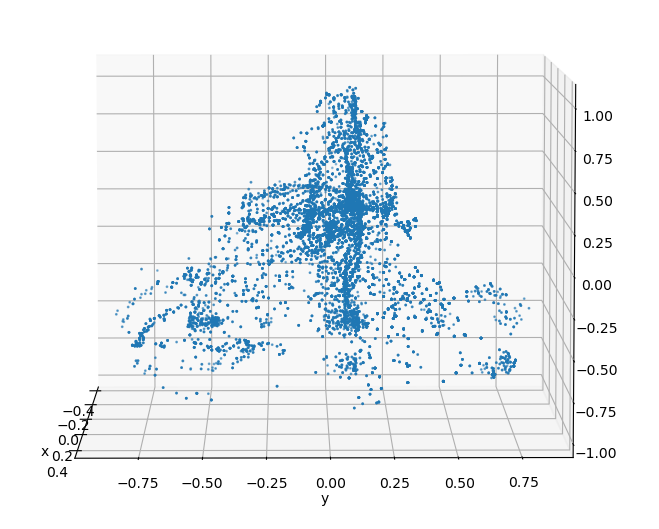
A complete model of a biker can be constructed by collecting and aligning point cloud data of bikers when viewed from various angles.
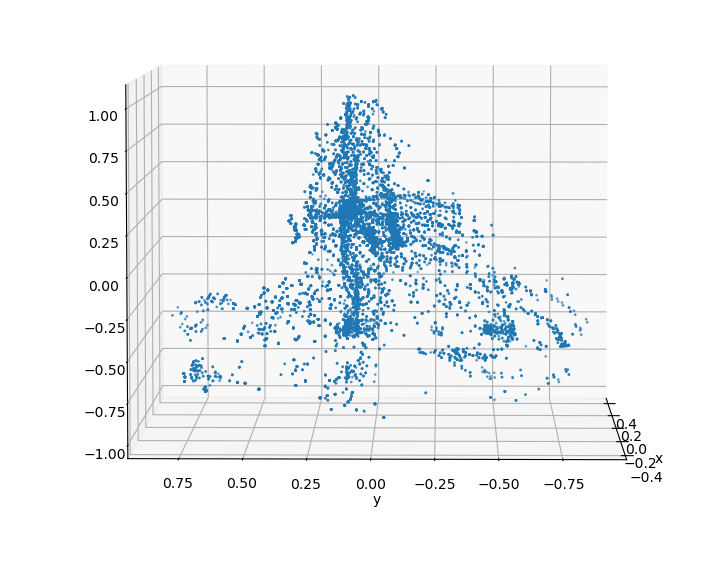
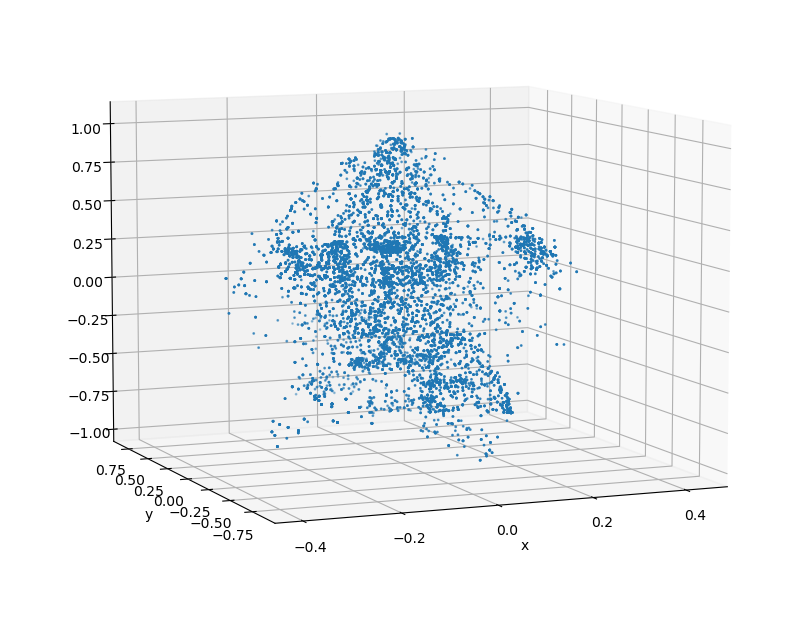
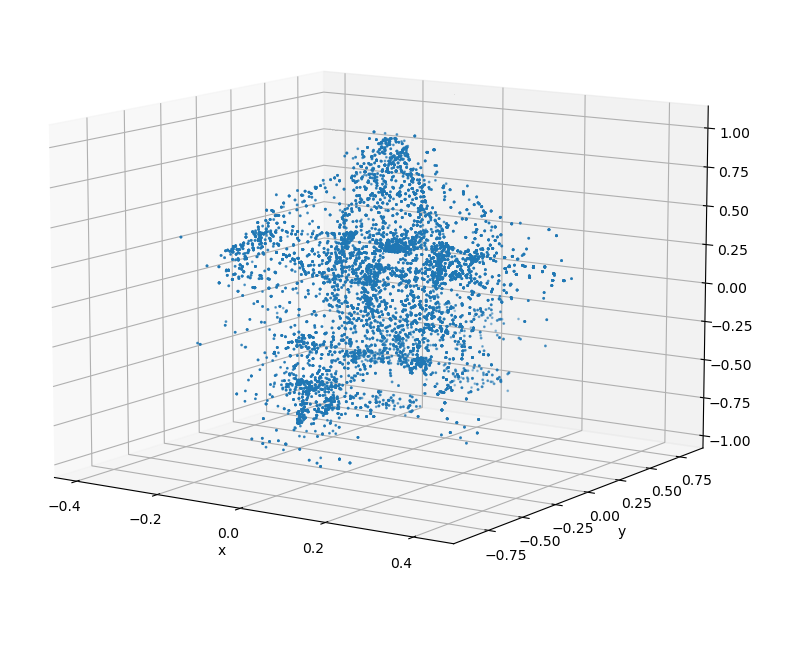
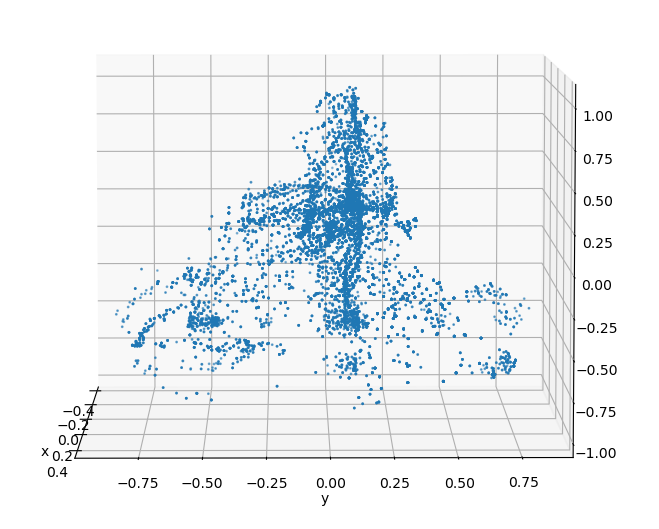
Sampling
From this baseline, the complete biker can be uniformly sampled to generate synthetic datasets. By applying occlusion to the cluster based on the viewing angle, a manufactured biker cluster can achieve a similar appearance to real data.
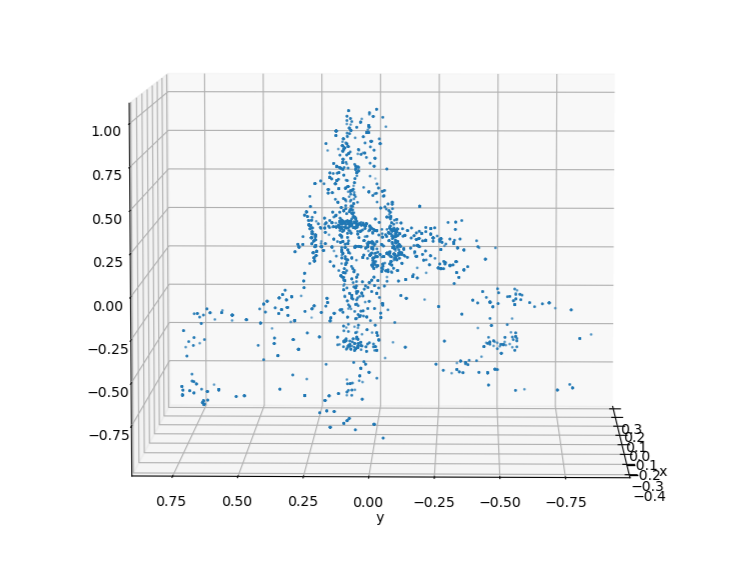
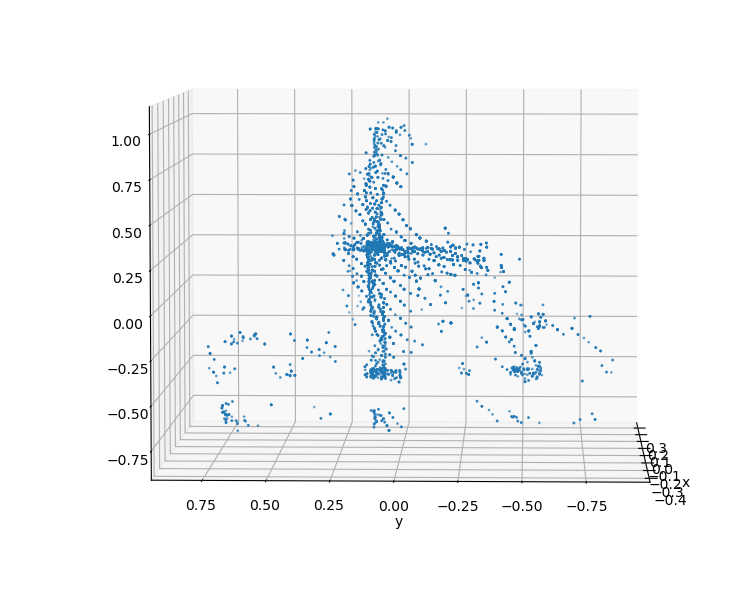
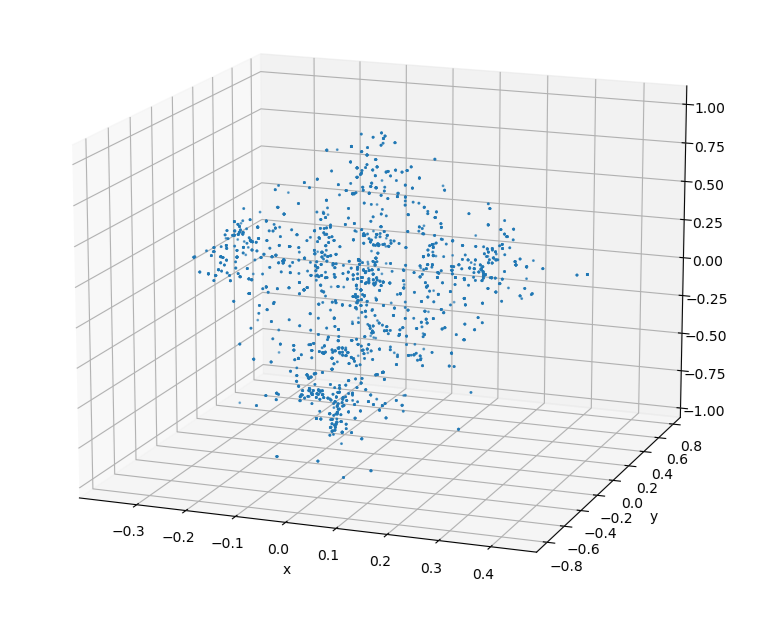
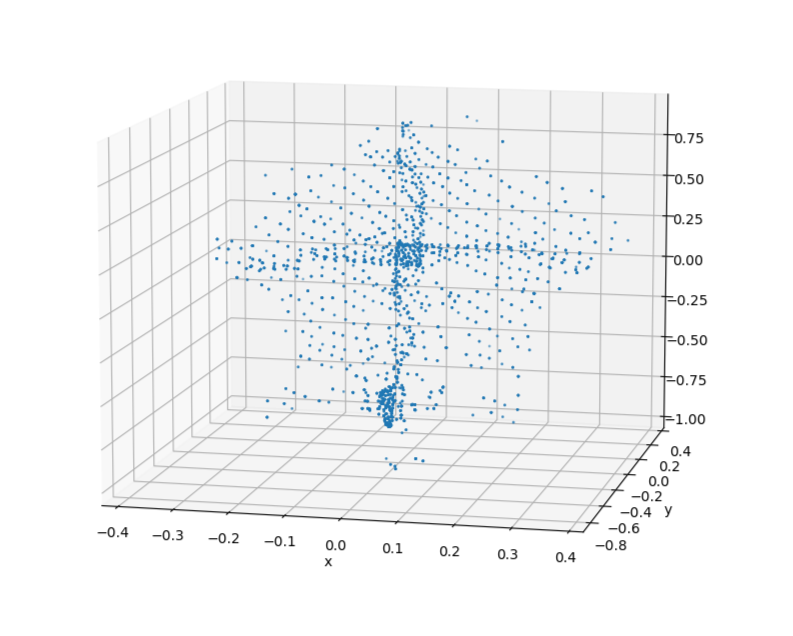
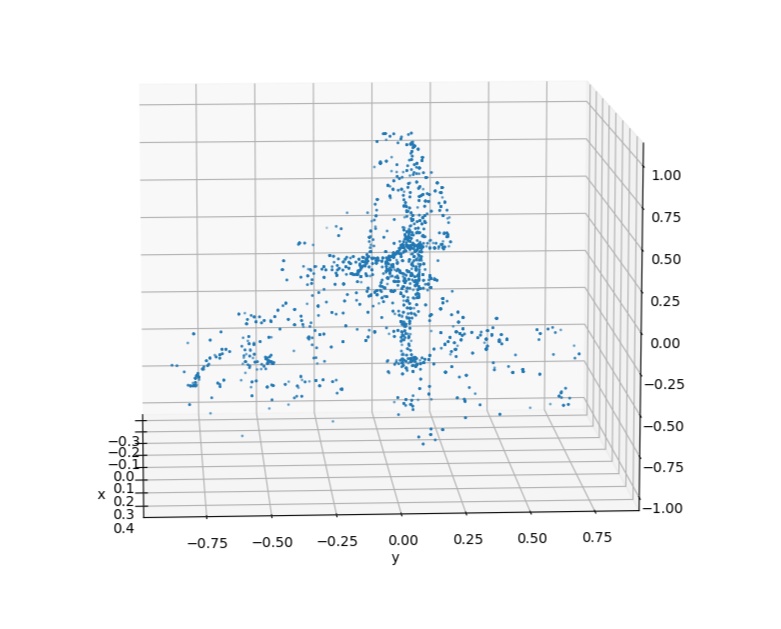
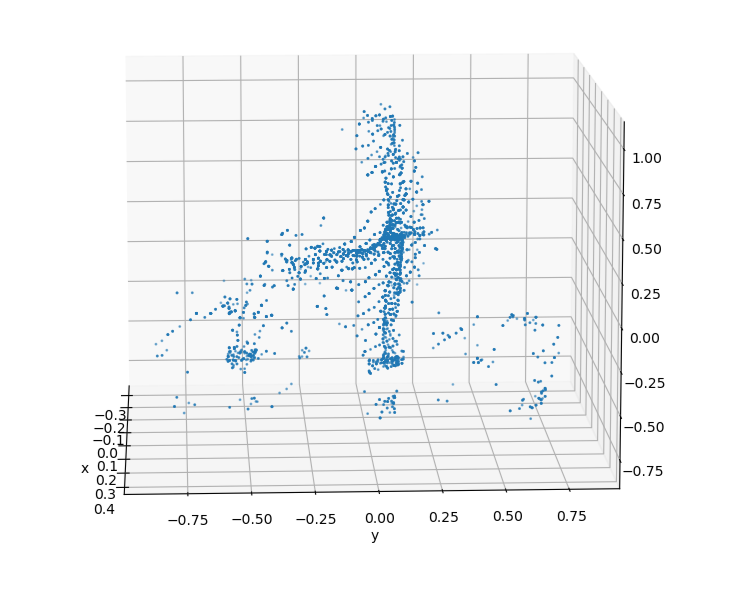
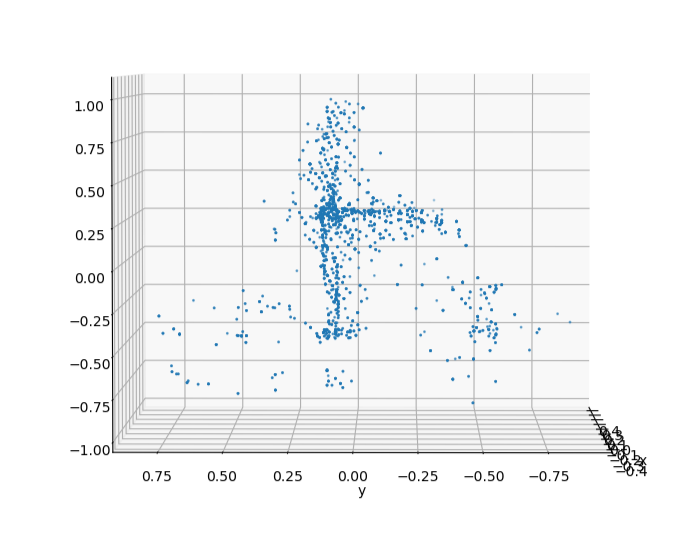
The clusters on the left are synthetic clusters. For comparison, examples of live-recorded clusters with the same viewing angle are displayed to the right.
Upon inspection, it can be seen that while the contours of the clusters are largely preserved, the uniform sampling of a merged cluster will cause the synthetic cluster to lose the unique laser pattern of the lidar. This deviation from real data could be significant enough to cause a reduction in model accuracy.
To address this, points in the baseline model are tagged according to their viewing angle during data collection. When generating synthetic clusters, the viewing angle of each point during data collection acts as weights during the weighted sampling process. The result is that points that have a similar viewing angle to the current simulation's viewing angle are more likely to be sampled. After applying occlusion to this weighted cluster, the result is synthetic clusters that better retain the lidar's laser pattern.
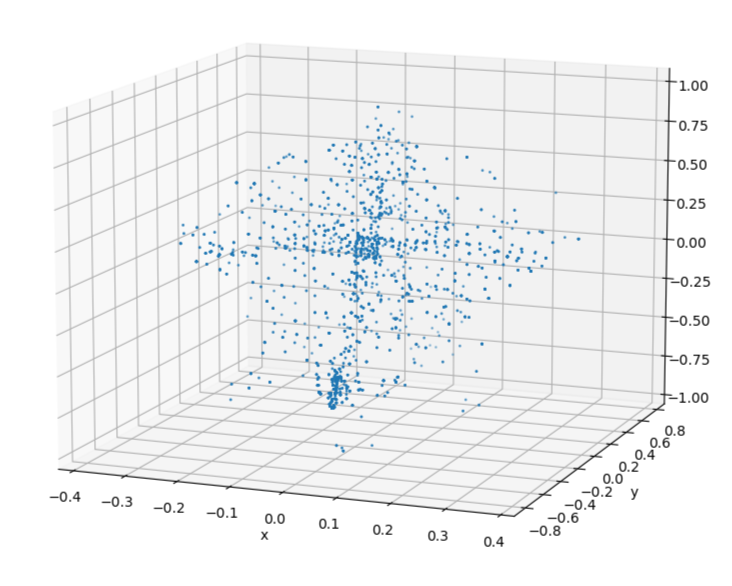
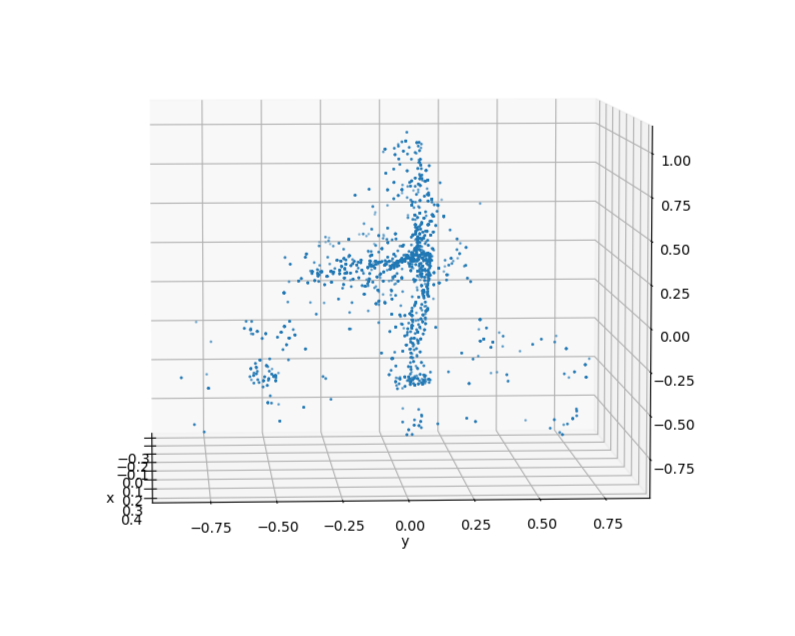
Using this method, the available biker data for training was expanded from 4681 manually collected clusters to 59356 clusters. The dataset breakdown is as follows:
| biker | non-biker | |
|---|---|---|
| Training | 46820 | 45828 |
| Validation | 6268 | 6238 |
| Testing | 6268 | 6237 |
Code for generating such clusters can be found here.
Model Architecture
During deployment, the on-board hardware often has limited computational resources — whether it's a restriction on time, memory, or hardware capability. Without GPU acceleration, a lightweight model is mandatory in order for the classifier to completely process all clusters in a given frame in a timely manner. A model architecture is presented that attempts to achieve acceptable levels of accuracy and speed when operating in a CPU only environment.
Related Work
The model modifies the existing PointNet architecture by Charles R. Qi et al.
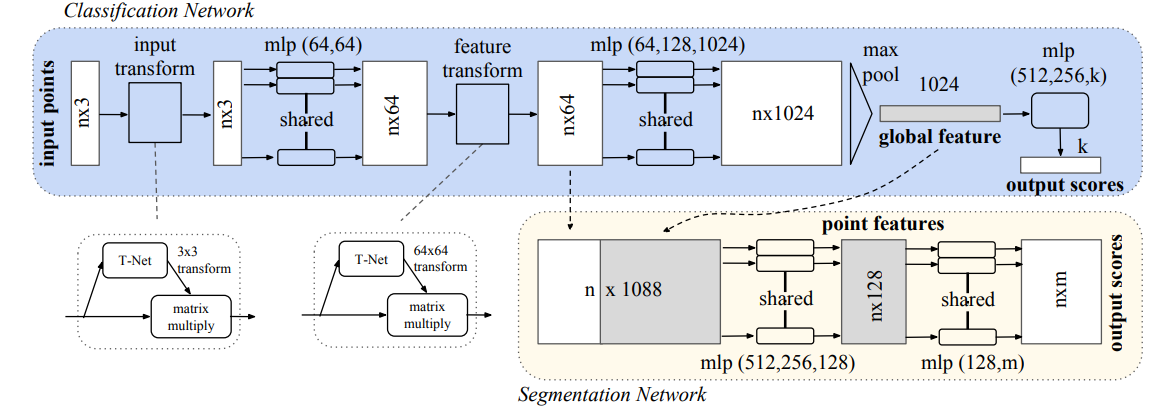
Objective
The goal for the model is to achieve real-time classification on CPU-only machines. The model is trained and evaluated on a LENOVO laptop with an 11th Gen Intel(R) Core(TM) i7-1165G7 processor without GPU acceleration. The estimated budget for the classifier during deployment is roughly 5 ms to classify all clusters present in the frame. On average, one can expect an average of 100 clusters in a given frame, which leaves a time budget of roughly 0.05 ms or 50 us per cluster.
Computational Graph

Results
Model Performance
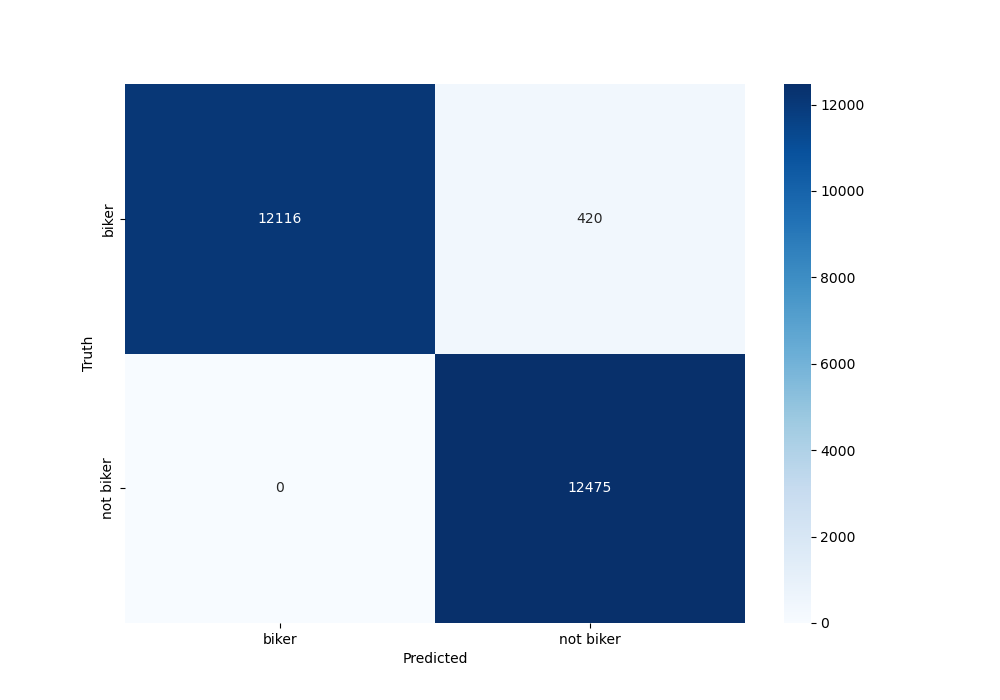
Speed Evaluation
Using the Pytorch profiler, the average inference time for 25011 clusters was 499 us.
While the model speed was not able to hit the desired benchmark of 50 us, during actual deployment there are ways to reduce the number of clusters that the model needs to classify — such as filtering out overly large clusters (closer biker clusters tend to have 900 to 1500 points). Doing so can greatly increase the time budget allotted to each classifier call.
Speed of Other Experimental Model Architectures
A logarithmic relationship could be observed between the inference speed and the number of operations in the model.
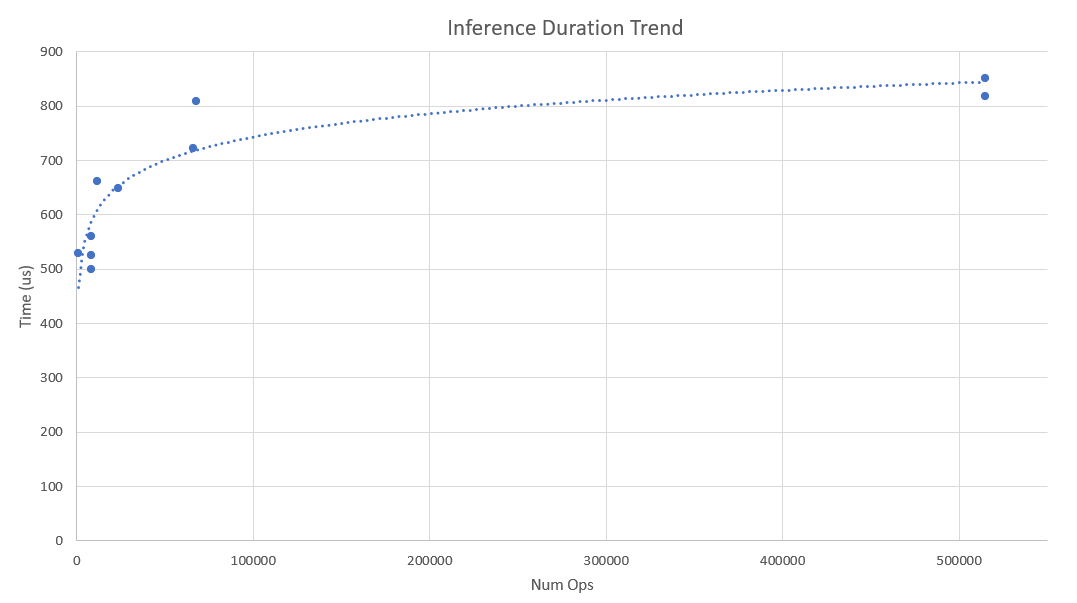
| Model | Parameters | Num Ops | Inference Time (us) |
|---|---|---|---|
| Final model | 132 | 8326 | 499 |
| pointnet_cls-v19 | 132 | 8326 | 526 |
| pointnet_cls-v18 | 132 | 1158 | 529 |
| pointnet_cls-v17 | 132 | 8326 | 560 |
| pointnet_cls-v12 | 113 | 23674 | 648 |
| pointnet_cls-v13 | 113 | 11898 | 661 |
| pointnet_cls-v21 | 292 | 65850 | 722 |
| pointnet_cls-v11 | 423 | 67944 | 808 |
| pointnet_cls-v20 | 2715 | 514844 | 818 |
| pointnet_cls-v9 | 2715 | 514844 | 851 |
Based on the observed trend, the pointnet_cls-v18 model is expected to have a lower inference time than all other architectures since it uses the least number of operations. However, that was not the case. This deviation could be attributed to the profiler precision or it could be a limit imposed by hardware capabilities.
The specific architecture for each model can be inspected here.
Future Work
Handling Merged Clusters
The training and testing dataset for bikers are comprised of clean data only. In other words, the biker clusters do not include any background or obstacle points. In order to better handle real world data, the model will need to be modified so it can isolate biker clusters when it has merged with other objects.
Increased Range of Synthetic Dataset
The data generation process can be further extended to generate synthetic datasets for clusters at various distances from the lidar by applying projection. This has yet to be implemented.
Quantization
By reducing the precision from float32 to fixed point or int8 one can expect the model to see significant improvements in speed at the potential expense of accuracy. This is particularly prevalent for hardware without FPUs or if memory usage is a concern.
Python to C
Python programs are slower than their C counterparts in general. By transferring the existing framework, which is written in Python, into C code, an improvement in speed is expected.
Confidence Level
During deployment, the classifier would be used to track bikers from frame to frame. The inclusion of confidence levels would be useful for such a purpose.
Termination Policy
During runtime, it is possible for the model to take more than the allotted time to process all clusters. In these cases, to avoid delaying the processing of the next frame, an efficient heuristic to quickly assign a label to the remaining clusters is necessary. Possible solutions include inheriting the labels from the previous frame; in the absence of prior labels, a search can be performed: if a cylindrical clusters exists and is surrounded by spherical clusters in the query, then it has a high likelihood of being a biker.
Hardware Change
Once the deployment hardware specs are determined, more profiling could be done on said hardware to get a better gauge of actual speed performance.